Large language models (LLMs) have raced from breakthrough to baseline in barely two years. Training techniques, open-source releases, and hyperscale infrastructure have driven down costs, nudging today’s frontier models towards commoditisation. In a recent episode of our podcast, Amadeus Venture Partner and “Father of Voice AI” Professor Steve Young mentions that “price competition will turn LLMs into a commodity.” – and it’s simple to see why.
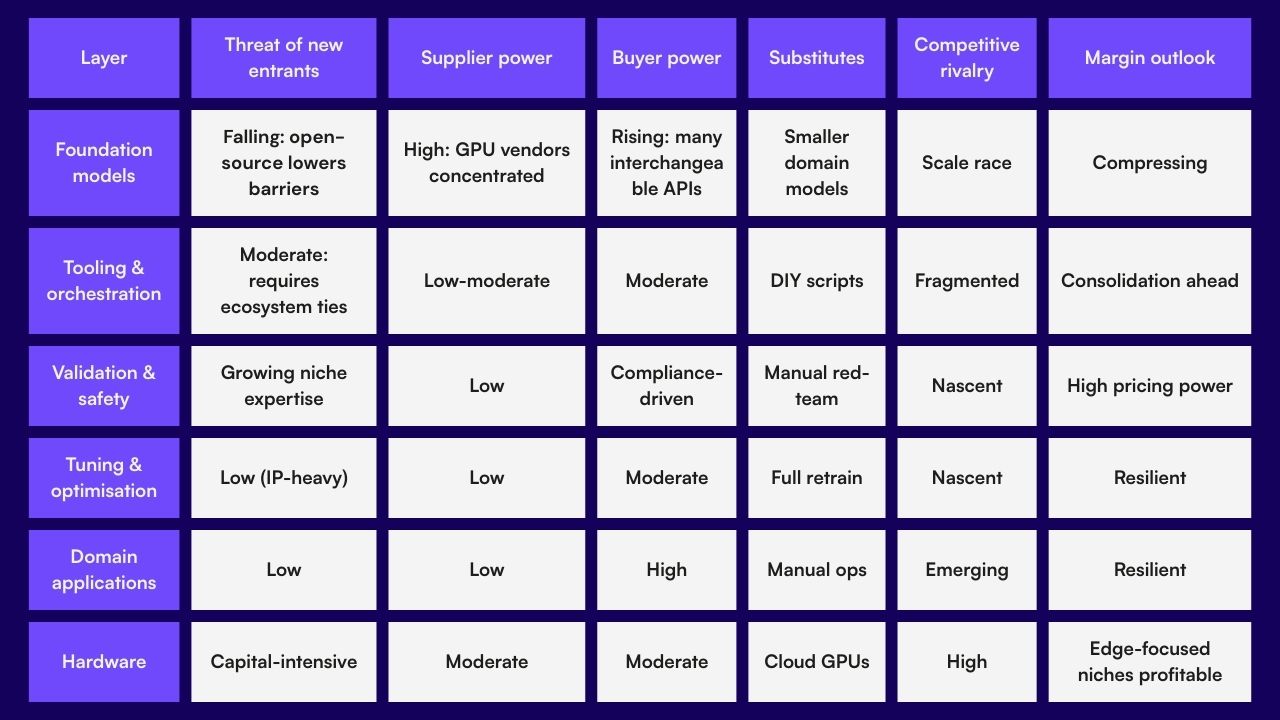
History suggests that, once a horizontal technology standardises, value leaks from core “pipes” (compute and generic models) and migrates to the “plumbing” (tooling, safety, data pipelines) and, ultimately, to the “fixtures” — domain-specific applications with unique distribution. Over the next three-to-five years the biggest profit pools are likely to form around: specialised data assets, workflow-integrated AI agents, efficient and cheaper tuning of models, evaluation/validation layers, and silicon tuned for efficient inference at the edge.
Some companies align neatly with these seams: PolyAI provides enterprise-grade voice AI agents; V7 supplies data-centric tooling that accelerates fine-tuning; Secondmind applies probabilistic machine-learning techniques to slash simulation overheads in automotive design; Safe Intelligence offers automated AI model validation; Inephany tunes models using less data and compute power for faster output; Unlikely AI blends neurosymbolic reasoning to curb hallucination; and XMOS delivers low-power processors that push LLM inference beyond the cloud.
As regulation such as the EU AI Act tightens, and as competitive pressure intensifies across the stack, defensibility will depend less on model scale and more on proprietary context, orchestration, and trust.
Where Next?
In technology, commoditisation creeps in when once-scarce capabilities become abundant. Less than two years separate GPT-4’s debut from the arrival of open weights (Llama 3, Mistral Medium). However, not all LLMs are created equal; ask identical analytical questions across Groq’s Mixtral demo and ChatGPT and you will see stark differences in latency, accuracy, and analysis.
Choosing which model now matters as much as accessing one. The crucial question is no longer if the value chain will rearrange, but where profits will settle next.
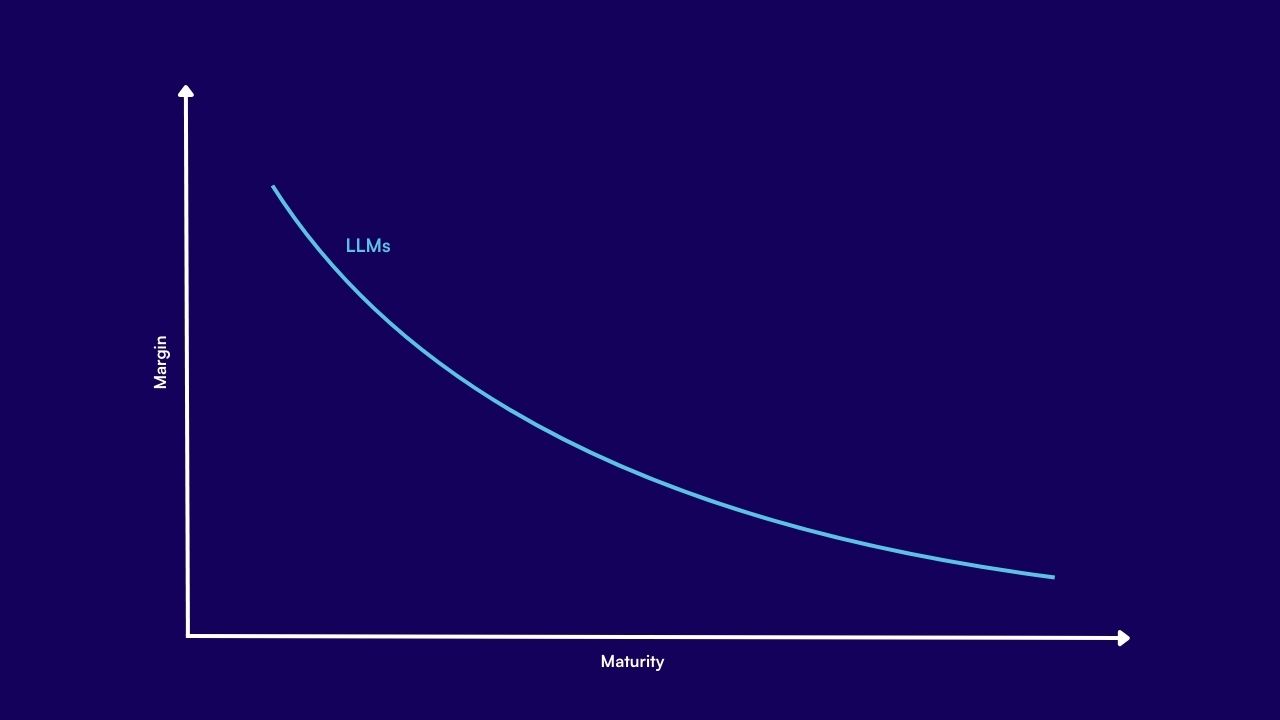
What is the Commoditisation Curve?
Borrowed from hardware economics, the curve tracks how margins erode as a product standardises, pushing surplus to adjacent layers. For LLMs the curve is bending towards data ownership, fine-tuning, and deployment tooling rather than sheer parameter count.